


Ci appare chiaro che gli eventi delle ultime settimane hanno portato a un cambiamento imponente nei comportamenti e abitudini di tutti noi e quindi, automaticamente, a un diverso rapporto nei confronti di negozi, banche, ed altre istituzioni.
Questo significa che i modelli di analisi dati che hanno fino ad oggi studiato il comportamento passato dei nostri clienti, collaboratori e fornitori, potrebbero essere inficiati dal cambio improvviso delle loro abitudini e priorità.
Essendo l’analisi predittiva uno dei nostri core businesses, ci siamo da subito attivati nella ricerca di soluzioni per mitigare l’impatto dei recenti avvenimenti su modelli già a regime all’interno delle aziende.
In questo articolo condivideremo alcune linee guida per identificare se si corre effettivamente il rischio di vedere i propri modelli predittivi intaccati in modo consistente e persistente dalla crisi sanitaria legata la COVID-19.
Avanzeremo inoltre alcune proposte su come affrontare il problema.
Il percorso di comprensione e risoluzione di questo problema è diviso in differenti step:
- analisi dell’impatto sulle specifiche variabili interne del modello
- trattamento delle variabili in ottica di “shock esterno”
- utilizzo di proxy per modellare lo shock
- modifiche dei modelli
Analisi dell’impatto sulle specifiche variabili interne del modello
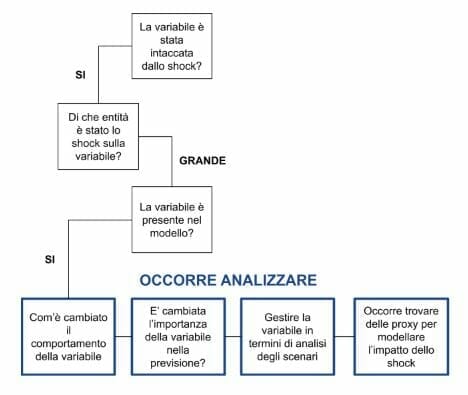
Nell’analizzare l’impatto dello shock sui modelli che l’azienda ha a regime bisogna porsi alcune domande:
- quali sono le variabili economiche e comportamentali che sono state intaccate dallo shock?
- di quanto è variato il comportamento di queste variabili rispetto allo storico?
- quali dei nostri modelli utilizzano variabili il cui comportamento è cambiato a causa dello shock?
- qual è l’impatto reale sul business dell’utilizzo di un modello falsato?
Una volta individuate quelle variabili che effettivamente hanno subito un consistente cambio di valore medio ed andamento, e quindi quali dei nostri modelli potrebbero essere stati falsati, ragioniamo su ulteriori quesiti:
- chi utilizza il modello e in che modo la sua ridefinizione impatterà l’operatore
- quali sono i rischi connessi alla ridefinizione del modello
- come possiamo esplorare le implicazioni dovute alle modifiche attuate sul modello durante l’intero processo di utilizzo del modello stesso
-
- ovvero, oltre alle persone che dovranno in prima persona apportare le modifiche, altri attori importanti sono: chi fornisce i dati, chi prepara i dati, chi gestisce altri tool che interagiscono anche in modo indiretto con il modello, chi usufruisce del modello, e infine in che modo le previsioni vengono utilizzate.
Sei interessato a conoscere le tecniche di analisi degli scenari per fronteggiare il calo di performance predittive dovuto al COVID-19?
Trattamento delle variabili in ottica di “shock esterno”
Partendo da una stessa variabile, si possono attuare trasformazioni matematiche del suo andamento che non ne modificano il significato intrinseco, ma possono renderla più robusta ad eventuali shock. Per mezzo di tali trasformazioni saremo in grado di circoscrivere l’impatto dello shock a un singolo punto nel tempo, piuttosto che all’intero periodo toccato dallo shock.
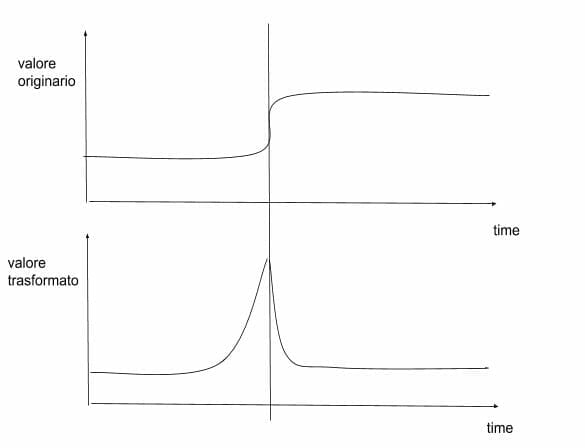
Per quanto riguarda le serie storiche, utilizzare strategie di differenziazione (differencing), che in condizioni normali ci aiutano nella stabilizzazione dei valori, in caso di shock causano invece un’amplificazione dell’errore predittivo, oltre a reiterarlo poi nel tempo.
Allo stesso modo, anche le strategie di rolling statistics potrebbero ampliare ulteriormente l’entità di errori predittivi.
Utilizzo di proxy per modellare lo shock
Il concetto alla base dell’utilizzo di proxies per simulare la risposta dei nostri modelli ad eventi estremi si basa sulla ricerca, o sulla creazione sintetica, di eventi passati che hanno avuto impatto simile rispetto a quello che stiamo studiando ora.
Vuoi scoprire di più sulle strategie di trasformazione delle variabili per minimizzare l’impatto degli shock e sull’utilizzo di eventi “proxy” per la modellazione degli shock?
Modifiche sui modelli
Appurate le considerazioni fatte nei precedenti paragrafi, dobbiamo ora cominciare a lavorare verso una soluzione del problema, ovvero come cambiare i nostri modelli durante e dopo l’avvenimento oggetto di attenzione.
Anche in questo caso dobbiamo innanzitutto porgerci alcuni quesiti:
- dovremmo includere i dati relativi al periodo di tempo intaccato dallo shock in analisi future, o dovremmo semplicemente rimuoverli? O flaggarli come anomali?
- ci aspettiamo di incontrare una situazione simile nuovamente in futuro?
- pensiamo che lo shock del mercato, e delle variabili ad esso connesse, sia circoscritto al singolo periodo di tempo, o ci aspettiamo che abbia ripercussioni sull’operato dei consumatori anche a shock terminato?
Dobbiamo inoltre considerare il fatto che lo shock potrebbe aver anticipato e amplificato la domanda per alcuni prodotti durevoli, che sarà necessariamente seguita da un periodo dove la domanda per quei beni rimarrà sotto la media storica e la media di quello stesso periodo prima dello shock.
Vuoi sapere quali sono le strategie intuitive e rapidamente attuabili per permettere di minimizzare l’impatto degli shock di mercato causati dal COVID?
Modelli durante e post shock
Per quei modelli la cui previsione è a breve termine, possiamo confutarne le performance predittive già durante il periodo stesso dello shock, o poco dopo. Un’altra tipologia di analisi di interesse per identificare possibili strategie per gestire lo shock è l’analisi dell’importanza delle variabili. Per quei modelli che ci permettono di estrarre la feature importance, sarà fondamentale individuare se, e in che modo, l’importanza delle singole variabili predittive è cambiata durante e dopo lo shock.
Re-framing del modello
Successivamente alle indagini portate a termine nei punti precedenti, vediamo ora alcune tipologie di modifiche che possiamo apportare al nostro modello per gestire lo shock, mantenendo performance predittive soddisfacenti.
Comments are closed.




